
TL;DR:
- Automated churn intervention detects at-risk customers and executes tiered, real-time engagement without manual intervention. It relies on four core data sources, event-driven pipelines, and AI risk scoring to prioritize actions and reduce false positives. Multi-channel outreach and ongoing outcome tracking improve recovery rates and continuous model improvement.
Automated churn intervention outreach is defined as a system that detects at-risk SaaS customers through behavioral signals, then executes tiered retention actions without waiting for a human to notice the problem. The industry term for this practice is "churn intervention automation," and it sits at the intersection of customer success operations and revenue intelligence. Automated workflows outperform manual outreach on three critical dimensions: response latency, intervention consistency, and audit defensibility. Teams that get this right can improve Net Revenue Retention by 4–8 points over manual processes. That gap is not a rounding error. It is the difference between a SaaS business that grows and one that quietly bleeds out.
How to automate churn intervention outreach in SaaS
Before you build a single workflow, you need the right data infrastructure in place. Churn intervention automation is fundamentally an infrastructure problem. Stale signals from batch scoring lead to missed intervention windows, and CS teams risk a 2–3 week delay behind the actual risk exposure when they rely on nightly data refreshes.

The four data sources you cannot skip
Your automation stack needs to pull from four core systems simultaneously:
- Product analytics (login frequency, feature adoption, session depth)
- CRM data (relationship history, open tickets, renewal dates)
- Billing system (payment failures, plan downgrades, cancellation events)
- Support logs (ticket volume, sentiment, unresolved escalations)
Each source tells a different part of the story. A customer who stops logging in but has no open tickets looks fine in your support queue. Only the combined signal reveals real risk.
Real-time pipelines vs. batch processing
Event-driven data pipelines are the standard for effective churn automation. A billing webhook trigger, such as a Stripe subscription-deleted event, can fire a personalized win-back email in under five seconds. Batch pipelines cannot compete with that speed. The goal is to measure time to outreach from the moment a risk threshold is breached, not from when a CSM happens to check their dashboard.
AI and ML components
The AI layer serves two functions: risk scoring and playbook recommendation. Risk scoring ranks accounts by churn probability using the behavioral signals above. Playbook recommendation tells your team or your automation exactly what to do next. Prediction alone is not sufficient. The AI must embed prescriptive next-best-actions into the workflow, not just surface a risk score and leave your team to figure out the rest.
| Infrastructure Layer | Function | Why It Matters |
|---|---|---|
| Event-driven data pipeline | Real-time signal capture | Eliminates 2–3 week batch delay |
| AI risk scoring engine | Ranks accounts by churn probability | Prioritizes CSM attention correctly |
| Playbook orchestration layer | Connects systems and triggers actions | Removes manual handoffs |
| Audit logging | Records all intervention activity | Supports governance and model tuning |
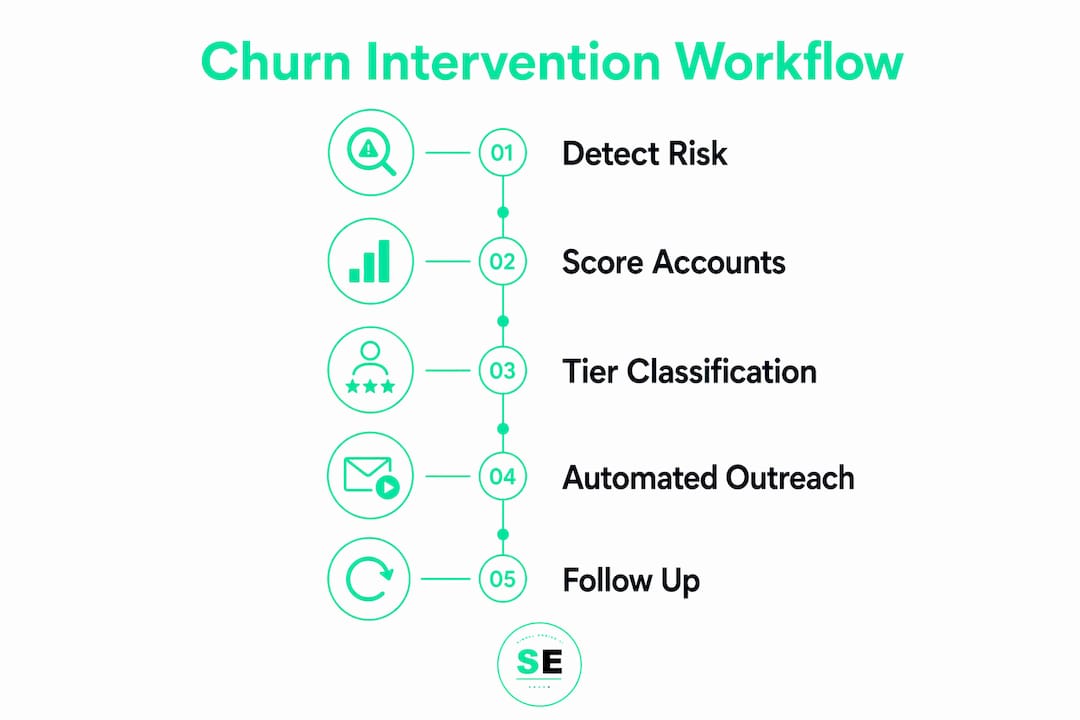
How to design tiered churn intervention workflows
The most effective intervention strategy for churn uses a tiered playbook that matches automation depth to customer risk level and annual recurring revenue. Not every at-risk account needs a phone call. Not every at-risk account can be saved by an email sequence. The tier determines the response.
Risk tier classification
A proven three-tier model works as follows:
- Amber tier: Health score drops below threshold for a sustained period. Automated touchpoints begin within 24 hours. These accounts get in-app messages, email sequences, and usage tips without requiring CSM involvement.
- Red tier: Health score drops sharply or multiple signals converge. A human CSM makes direct contact within 24 hours. Faster imperfect calls outperform polished delayed emails at this tier. Speed matters more than polish.
- Enterprise Amber tier: Any at-risk signal on a high-ARR account triggers a personal call with escalation protocols if there is no response within 48 hours.
Pro Tip: Measure your intervention clock from the moment the risk threshold is breached, not from when a CSM views the alert. That single operational change reveals how much time your team is actually losing.
The dwell time rule
One of the most overlooked design decisions in churn automation is the dwell time rule. Threshold-based triggers combined with a 48–72 hour dwell time reduce false positives caused by temporary health score dips from weekends, holidays, or platform outages. Requiring a risk score to stay below threshold for the full dwell period before firing an alert prevents your CS team from chasing noise. This single rule can dramatically reduce alert fatigue.
Workflow timing benchmarks
| Tier | First Action | Action Type | Escalation |
|---|---|---|---|
| Amber | Within 24 hours | Automated email + in-app message | CSM review at 72 hours if no engagement |
| Red | Within 24 hours | Human CSM call or personalized email | Manager escalation at 48 hours |
| Enterprise Amber | Within 24 hours | Personal CSM call | Executive escalation if no response |
Tracking intervention outcomes at each tier is not optional. Recording intervention types, assignees, timestamps, and outcomes feeds back into your churn model and prevents your playbook from going stale. A playbook that never updates is a playbook that stops working.
Which outreach channels maximize churn intervention recovery?
Channel selection is where most SaaS teams leave recovery rate on the table. Multi-channel intervention sequences combining in-app messages, email, and direct CSM outreach recover 31–38% of flagged accounts. Email-only outreach recovers roughly 12%. That gap is large enough to justify the added complexity of a multi-channel approach.
Building your channel sequence
A practical automated sequence for Amber-tier accounts looks like this:
- Day 1: In-app message surfacing a specific usage gap ("You haven't used [Feature X] in 14 days. Here's a quick guide.")
- Day 3: Personalized email from the assigned CSM's address, referencing the customer's actual use case
- Day 7: Second email with a concrete offer, such as a live training session or a feature walkthrough
- Day 10: CSM task created automatically for a direct follow-up call if no engagement has occurred
Pro Tip: Your first automated message should diagnose, not check in. "We noticed your team hasn't activated the reporting module" outperforms "Just checking in to see how things are going" every time. Specificity signals that you are paying attention.
Messaging aligned to churn drivers
Generic check-in messages fail because they do not address the actual reason a customer is drifting. Match your message to the churn driver:
- Activation failure: Send a targeted onboarding resource or schedule a setup call
- Value mismatch: Share a case study from a similar customer who solved the same problem
- Competitive pressure: Highlight a recent product update that addresses the gap they mentioned
- Budget concerns: Proactively offer a plan review before they cancel
Personalization at this level requires that your automation has access to the CRM context and product analytics data discussed earlier. The messaging layer and the data layer are not separate problems.
How to optimize automated churn workflows over time
Automation that runs without feedback loops degrades. The accounts you save today teach you how to save more accounts tomorrow, but only if you capture the right data. Automated systems must record intervention details and 30-day outcomes for continuous model tuning. Without outcome data, your churn model trains on inputs but never learns from results.
Common operational pitfalls
- Delayed human involvement: Waiting for a perfect email draft costs you the intervention window at Red tier. Send the imperfect message fast.
- Batch-based scoring: Nightly score recalculation means a customer who cancels at 9 a.m. may not appear in your queue until the next morning.
- Alert fatigue: Too many low-confidence alerts train your CS team to ignore the queue. The dwell time rule and confidence thresholds fix this.
- Static playbooks: A playbook written in january that has never been updated based on outcome data will underperform by the following quarter.
Troubleshooting false positives
False positives waste CSM time and erode trust in the system. Two fixes work reliably. First, raise your risk score confidence threshold so only high-probability signals fire alerts. Second, apply the 48–72 hour dwell time rule so transient dips do not trigger full intervention sequences.
"Automation wins by providing audit trails that improve governance and make churn interventions defensible for executive reporting."
Audit logs serve two audiences: your operations team, which uses them to tune the model, and your executive team, which uses them to report on retention program effectiveness. Both audiences need the same data. Build your logging to serve both from the start.
Automated at-risk account alerts that include timestamps, assignees, and resolution outcomes give you the raw material to answer the question every VP of Customer Success eventually asks: "Which interventions actually work?"
Key takeaways
Automated churn intervention outreach works because it combines real-time risk detection, tiered playbooks, and multi-channel sequences to recover at-risk accounts faster and more consistently than any manual process can.
| Point | Details |
|---|---|
| Real-time pipelines are non-negotiable | Batch scoring creates a 2–3 week delay that kills intervention effectiveness. |
| Tiered playbooks match response to risk | Amber accounts get automation; Red accounts get a human call within 24 hours. |
| Multi-channel sequences outperform email alone | In-app, email, and CSM outreach combined recover 31–38% of flagged accounts. |
| Dwell time rules reduce false positives | Requiring 48–72 hours below threshold prevents alerts from transient health score dips. |
| Outcome logging drives continuous improvement | Recording 30-day results feeds back into model tuning and keeps playbooks current. |
Why speed beats perfection in churn intervention
I have watched CS teams spend three days crafting the perfect save email while the customer quietly submitted a cancellation request. The instinct to get the message right is understandable. The outcome is predictable. Speed wins at Red tier, every time.
The harder lesson is about where automation actually breaks down. It rarely breaks at the technology layer. It breaks at the workflow design layer, specifically when teams treat churn alerts as notifications rather than triggers. A raw health score alert sitting in a Slack channel is not an intervention. An alert that automatically creates a CSM task, pre-populates the customer context, and fires an in-app message while the CSM prepares for the call is an intervention.
Embedding churn risk signals into daily workflows with prescribed next actions is the design principle that separates teams with 35% recovery rates from teams with 12% recovery rates. The technology is available to everyone. The operational discipline to use it correctly is not.
For enterprise accounts, I would argue that automation should do less, not more. The value of a personal call from a senior CSM on a high-ARR account at risk cannot be replicated by a sequence. Automation's job at that tier is to make sure the call happens fast and that the CSM walks in with full context. That is a support role, not a replacement role.
— Bernard
Signalengine catches churn before your team even sees it
Signalengine is built for SaaS teams that need churn intervention automation without a six-month implementation project. It scores customer behavior in real time, flags accounts before they reach the cancellation stage, and triggers outreach sequences automatically.
The churn prediction tools inside Signalengine give your CS team a live risk queue with prescribed next actions, not just raw scores. You get multi-channel outreach triggers, audit logs, and outcome tracking built in. For SaaS teams that want to see it in action, the revenue intelligence platform starts at $49/month with no setup fees and no data science team required.
Ready to Stop the Revenue Leak?
Signal Engine gives small and local businesses 31 AI-powered tools to score leads by buying intent, predict churn before it happens, auto-generate email and SMS campaigns, and recover missed calls automatically — all in one dashboard starting at $49/month.
Start your free 7-day trial — no credit card required. Setup takes 5 minutes.
FAQ
What is automated churn intervention outreach in SaaS?
Automated churn intervention outreach is a system that detects at-risk customers through behavioral and billing signals, then executes tiered retention actions, such as in-app messages, emails, and CSM tasks, without manual triggering.
How fast should automated churn outreach fire after a risk signal?
Amber-tier accounts should receive an automated touchpoint within 24 hours of a sustained risk signal. Red-tier accounts require human CSM contact within 24 hours, as AI-driven workflows can execute full retention interventions within 60 minutes of a churn risk flag.
What is a dwell time rule in churn automation?
A dwell time rule requires a customer's health score to stay below a risk threshold for 48–72 hours before an alert fires. This prevents false positives from temporary dips caused by weekends, holidays, or platform outages.
How much better is multi-channel outreach than email alone?
Multi-channel sequences combining in-app messages, email, and CSM outreach recover 31–38% of flagged accounts. Email-only outreach recovers approximately 12% of the same accounts.
Why do audit logs matter for churn intervention automation?
Audit logs record intervention types, assignees, timestamps, and 30-day outcomes. That data feeds back into churn model tuning and gives executive teams defensible evidence of retention program effectiveness.